Convergent Evolution: How Different Language Models Learn Similar Number Representations
Language models develop Fourier spikes at periods $T = 2, 5, 10$ when representing numbers. We show this is universal: every pretrained LLM we examine, every classical word-embedding baseline, and even the raw number-token frequency distribution with no model at all develop the same spikes. But a stronger property, the linear separability of numbers by their residue mod $T$, is selective: only some systems achieve it. We prove the two properties can dissociate arbitrarily, identify what causes the gap in controlled pretraining runs, and show that multi-token addition training reaches the same endpoint through a different mechanism.
A suspiciously universal pattern
A growing body of interpretability work has found that language models represent numbers using periodic features. Take the embedding of each integer token, run a discrete Fourier transform over the sequence of embeddings, and you reliably see spikes at periods T = 2, 5, 10. This has been observed in GPT-2, Llama, and other Transformers, and interpreted as evidence that next-token prediction teaches models something structural about numbers.
We started with a simple question: how far does this generalize? So we looked at almost everything we could get our hands on. Transformers of many scales (GPT-2, GPT-OSS, Llama-3, Llama-4, DeepSeek-V3), non-Transformer LLMs (Mamba, Falcon-Mamba, xLSTM, Kimi-Linear), and classical word embeddings (GloVe, FastText).
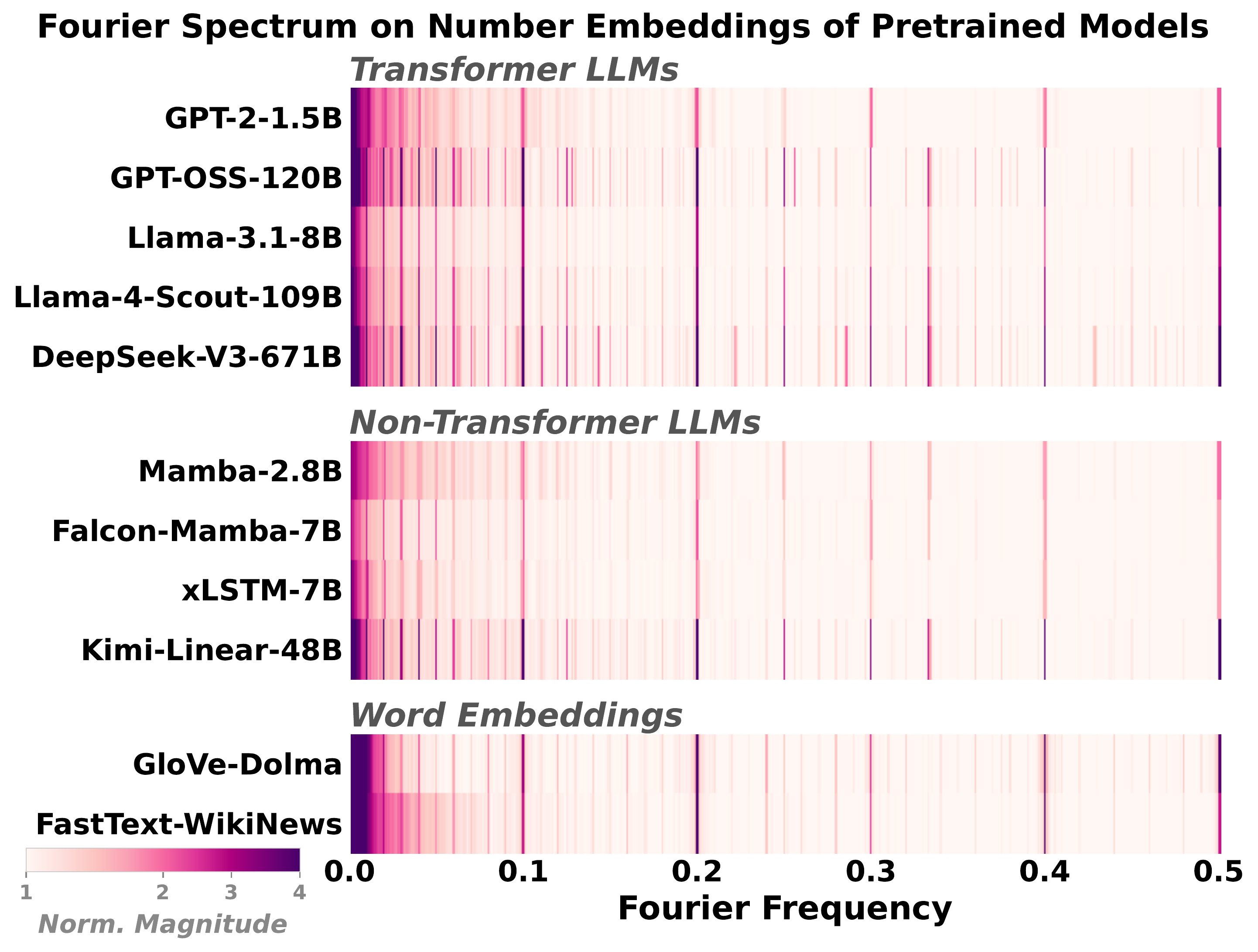
Every system showed the same spikes. The shared trait is not a deep architectural property; it is a consequence of how numbers are distributed in text. We will see in a moment that even the raw number-token frequency distribution, with no model at all, has the same spikes.
If a quantity that any reasonable model would inherit from training data already has the signature, what exactly are we measuring when we see it in a trained model?
Spectral vs. geometric convergence
This motivates a distinction we make throughout the paper.
- Spectral convergence. The embedding has Fourier spikes at the expected periods.
- Geometric convergence. The embedding actually encodes n mod T as a linearly decodable quantity. A linear probe (we report Cohen's κ, which corrects for chance) can classify numbers by their residue mod 2, 5, or 10.
The first is a statement about the spectrum. The second is a statement about geometry: period-T structure is only useful if numbers sharing the same residue cluster together in embedding space.
A theorem: spikes are necessary but not sufficient
The main theoretical result in the paper formalizes this gap. Let $\{e(n)\}_{n=0}^{N-1}$ be the embeddings of numbers 0 through $N-1$, and let $C_r = \{n : n \equiv r \pmod T\}$ be the mod-$T$ residue classes. Define the discrete Fourier transform
$$F_\nu = \tfrac{1}{\sqrt{N}} \sum_{n=0}^{N-1} e(n) \, e^{-2\pi i \nu n}, \qquad \Phi_T = \sum_{\ell=1}^{T-1} \|F_{\ell/T}\|^2,$$
so $\Phi_T$ is the total Fourier power at the harmonics of period $T$.
To talk about how the embeddings are arranged geometrically, we need two standard quantities from linear discriminant analysis. Let $\mu_r = \tfrac{1}{|C_r|} \sum_{n \in C_r} e(n)$ be the mean embedding of residue class $r$, and let $\mu = \tfrac{1}{N} \sum_n e(n)$ be the grand mean. The between-class scatter $S_B$ measures how spread apart the class means are, and the within-class scatter $S_W$ measures how spread out the embeddings are around their own class mean:
$$S_B = \tfrac{1}{T} \sum_{r=0}^{T-1} (\mu_r - \mu)(\mu_r - \mu)^\top, \qquad S_W = \tfrac{1}{N} \sum_{r=0}^{T-1} \sum_{n \in C_r} (e(n) - \mu_r)(e(n) - \mu_r)^\top.$$
Linear separability of the residue classes is governed by how large $S_B$ is relative to $S_W$. If the class means are far apart (large $S_B$) and the within-class clouds are tight (small $S_W$), a linear probe works well. If the class means coincide ($S_B = 0$) or the within-class clouds dwarf the gap between means, no linear probe can do better than chance.
Theorem 1 (Fourier spikes are necessary but not sufficient).
- Necessity. If $\Phi_T = 0$, then $S_B = 0$, and no linear probe can classify $n \bmod T$ above chance.
- Insufficiency. For any $T \ge 2$, any $C > 0$, and any $\varepsilon > 0$, there exist $N$ divisible by $T$ and embeddings $e(n)$ with $\Phi_T > C$ such that no $T$-class linear classifier achieves accuracy above $1/T + \varepsilon$. In other words, the Fourier spike can be arbitrarily large while linear probes do no better than random guessing by more than $\varepsilon$.
The necessity direction follows from a Fourier identity (Lemma in the paper) that gives $\mathrm{Tr}(S_B) = \Phi_T / N$. The insufficiency direction is the interesting part. The paper gives an explicit family of counterexamples.
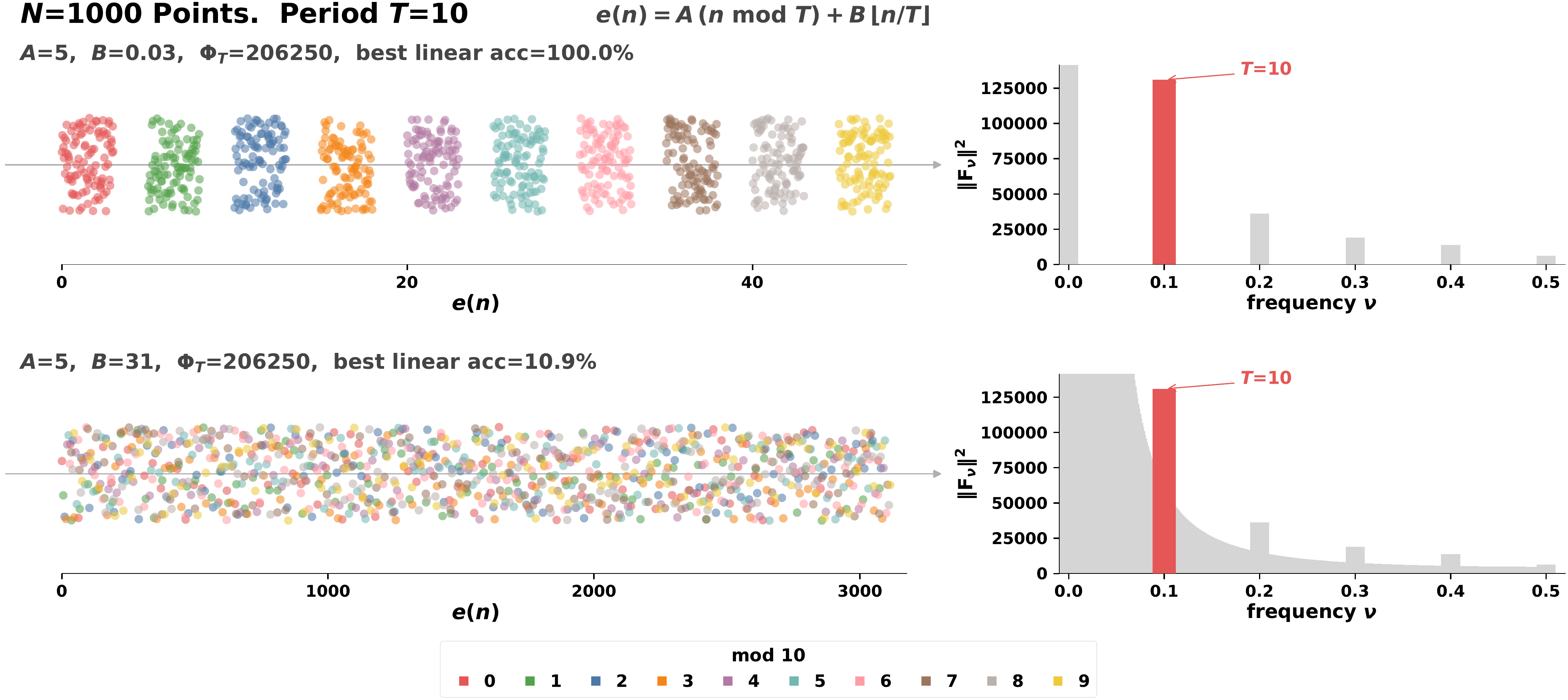
The counterexample, in pictures
Every number $n \in \{0, \dots, N-1\}$ decomposes uniquely as $n = r + mT$ with residue $r \in \{0, \dots, T-1\}$ and block index $m \in \{0, \dots, K-1\}$ where $K = N/T$. Pick two vectors $A$ and $B$ and set
$$e(n) = A r + B m.$$
The term $Ar$ encodes the residue and contributes to $S_B$ (and therefore to $\Phi_T$). The term $Bm$ varies within each residue class and contributes only to $S_W$. The two pieces live on independent axes, so scaling $B$ moves the embeddings along a direction that is invisible to the Fourier spike but arbitrarily large in the within-class scatter.
The paper also gives matching Fisher-discriminant bounds that sharpen the picture:
$$\frac{1}{(T-1)\,\mathrm{cond}(S_W)} \cdot \frac{\Phi_T}{N \, \lambda_{\min}(S_W)} \;\le\; \lambda_{\max}(S_W^{-1} S_B) \;\le\; \frac{\Phi_T}{N \, \lambda_{\min}(S_W)}.$$
The Fourier power sets $\Phi_T$, but the conditioning of $S_W$ sets the gap between the upper and lower bounds. Two models with similar Fourier spectra can have wildly different probe accuracy depending on how the periodic signal aligns with the within-class noise.
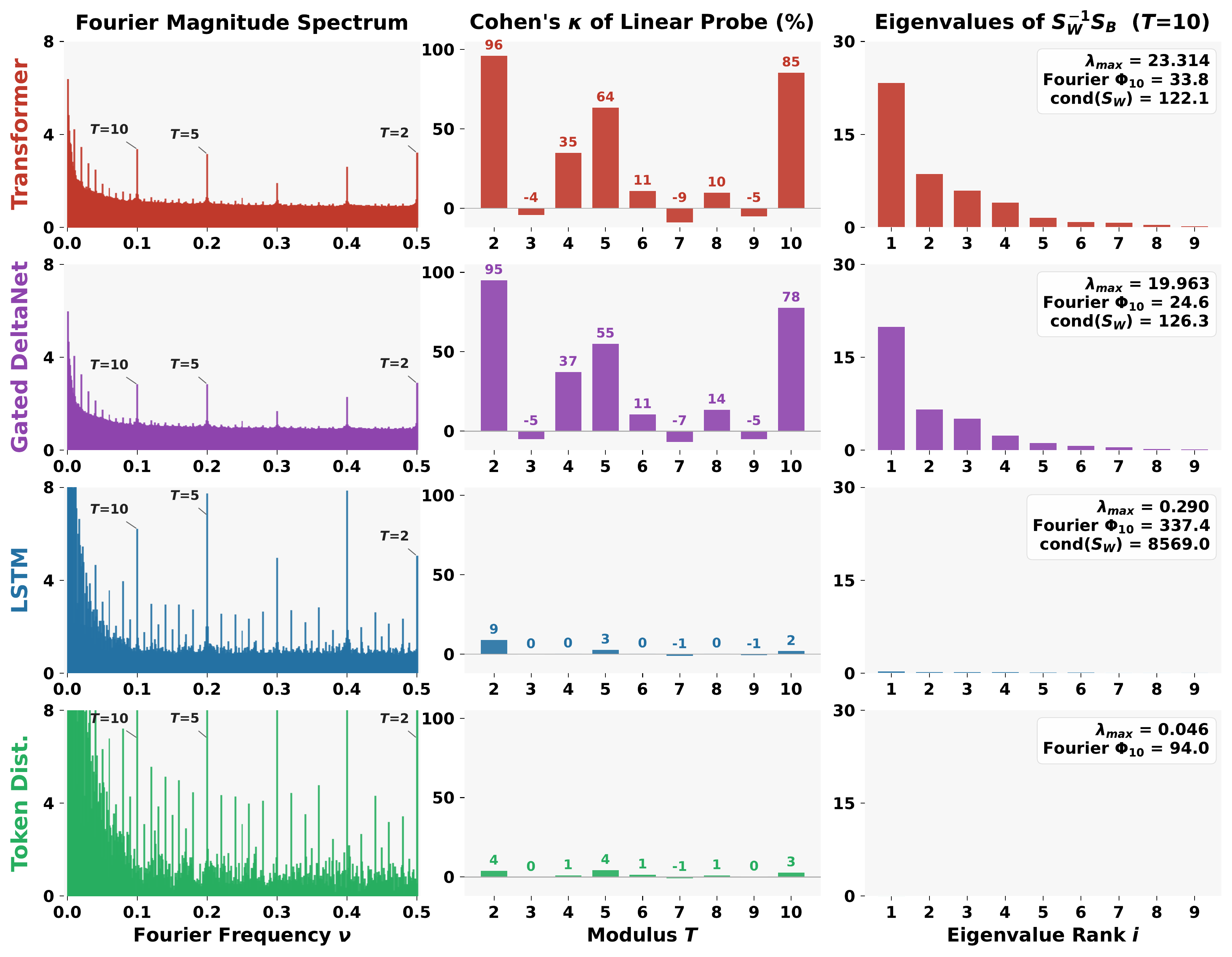
What separates the two? Controlled 300M-parameter runs
To isolate what drives geometric convergence, we trained 300M-parameter models from scratch on 10B tokens of FineWeb-Edu under tightly controlled conditions, varying data, architecture, and optimizer one factor at a time.
Data: which co-occurrence signals matter?
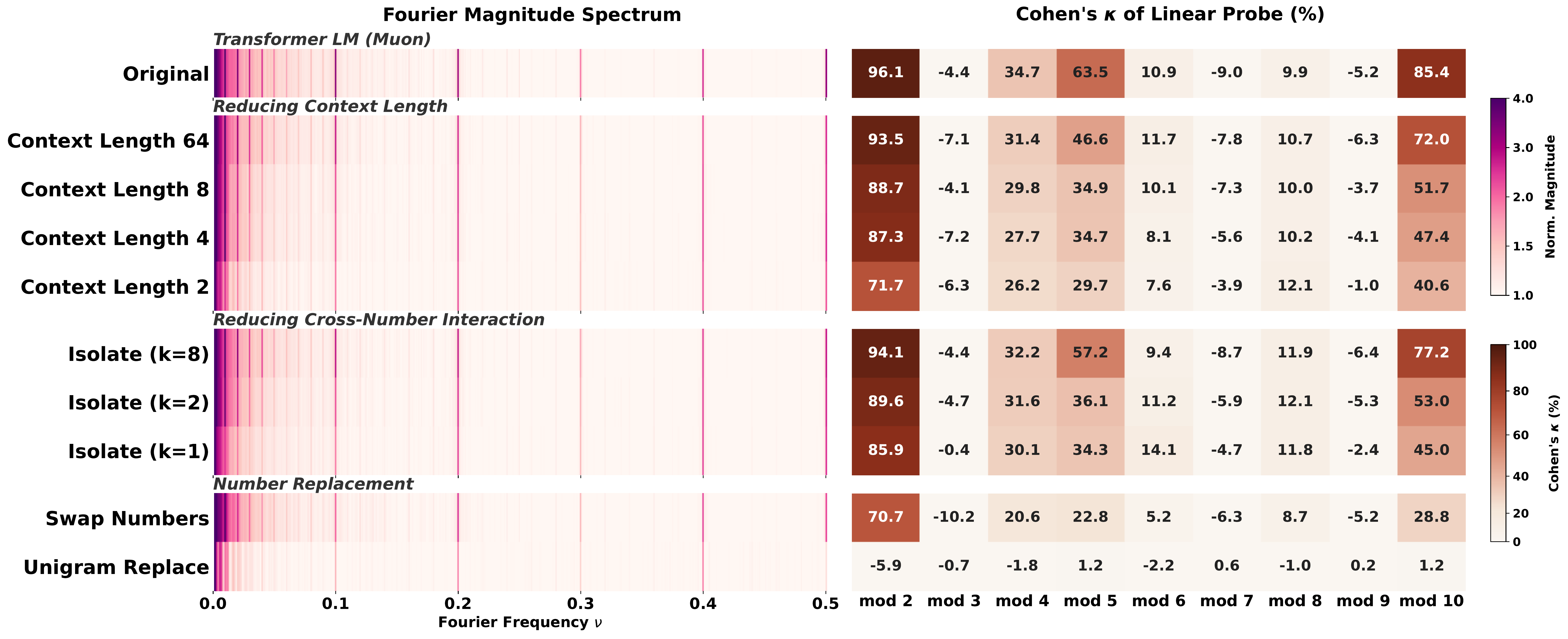
Swap Numbers (destroying text-number association) drops κ from 85.4 to 28.8 at $T=10$; Unigram Replace (destroying all co-occurrence) falls to chance.We designed a series of ablations that each remove one specific property of the training corpus. Swap Numbers preserves number $n$-gram statistics but breaks the link between numbers and their text context. Unigram Replace resamples each number token independently from its marginal distribution, destroying all co-occurrence. Isolate-k packs sequences so that each contains at most $k$ number tokens, controlling cross-number interaction. ContextLength-$\ell$ restricts the context window to $\ell$ tokens.
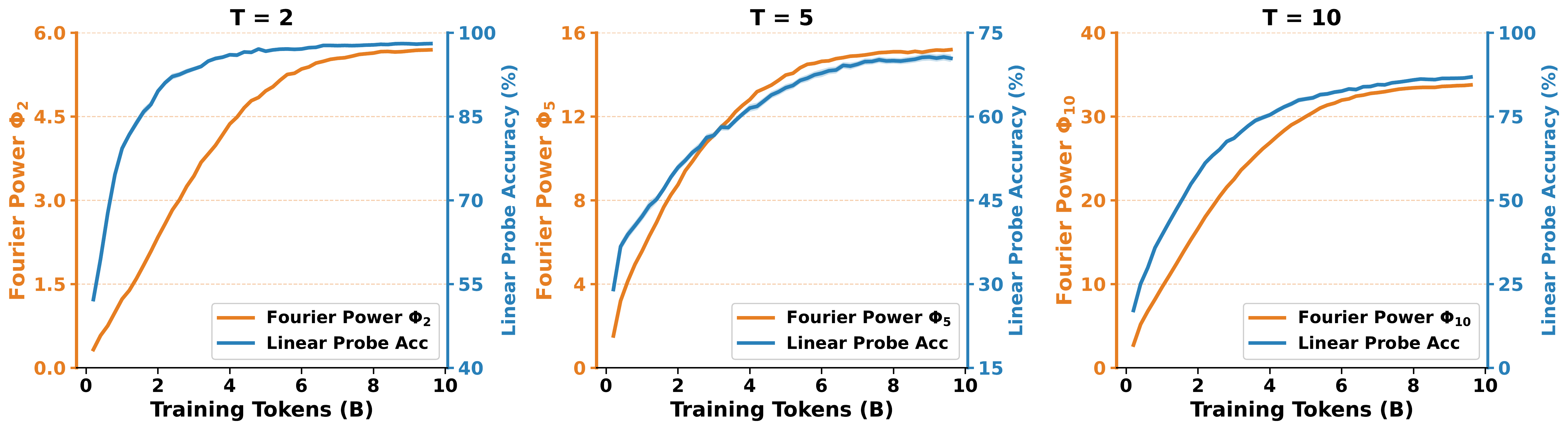
Each perturbation degrades linear probe accuracy. None of them noticeably changes the Fourier spectrum. Put differently: the spikes are cheap, the geometry is earned. And no single signal is doing all the work. Text-number co-occurrence, broader context, and cross-number interaction each contribute something, and removing any one of them leaves probing weaker than the original setting.
We view this as structure attribution. Influence functions attribute predictions to individual training examples. Our controlled perturbations do the analogous thing at the level of representations: they attribute learned features to specific structural properties of the data distribution.
Architecture and optimizer: not all sequence models are equal
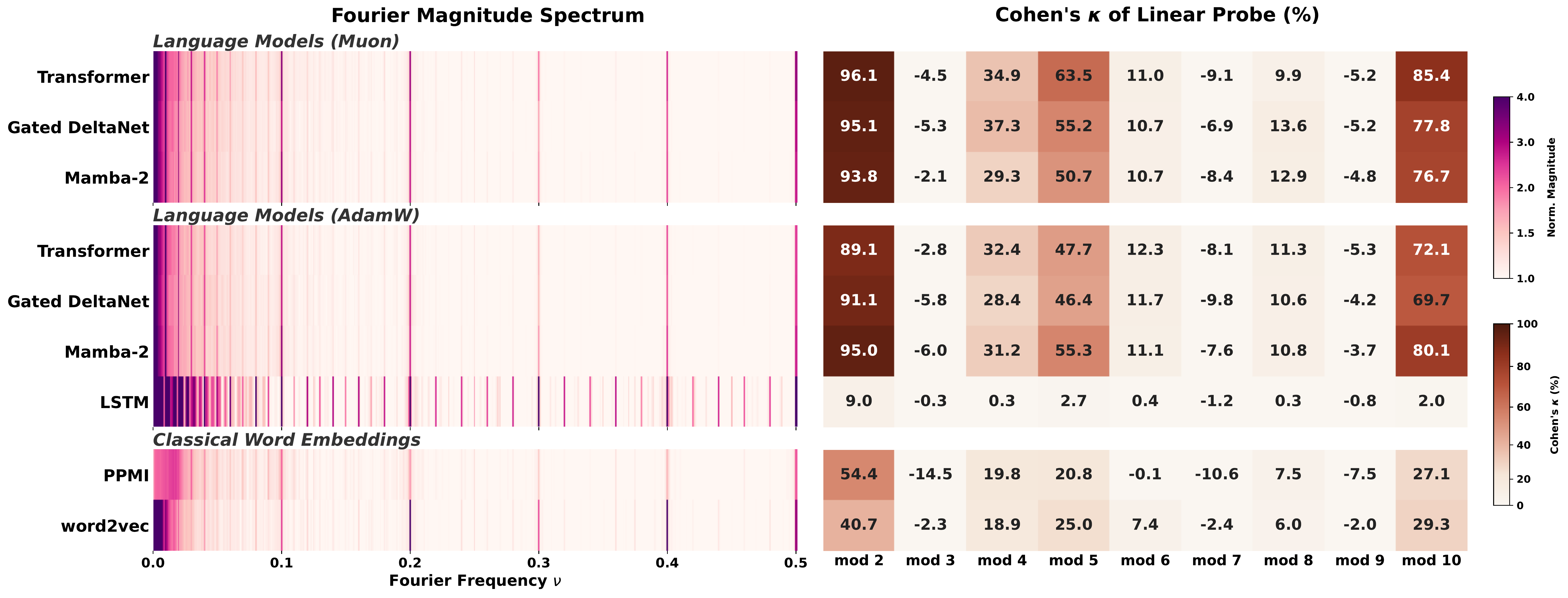
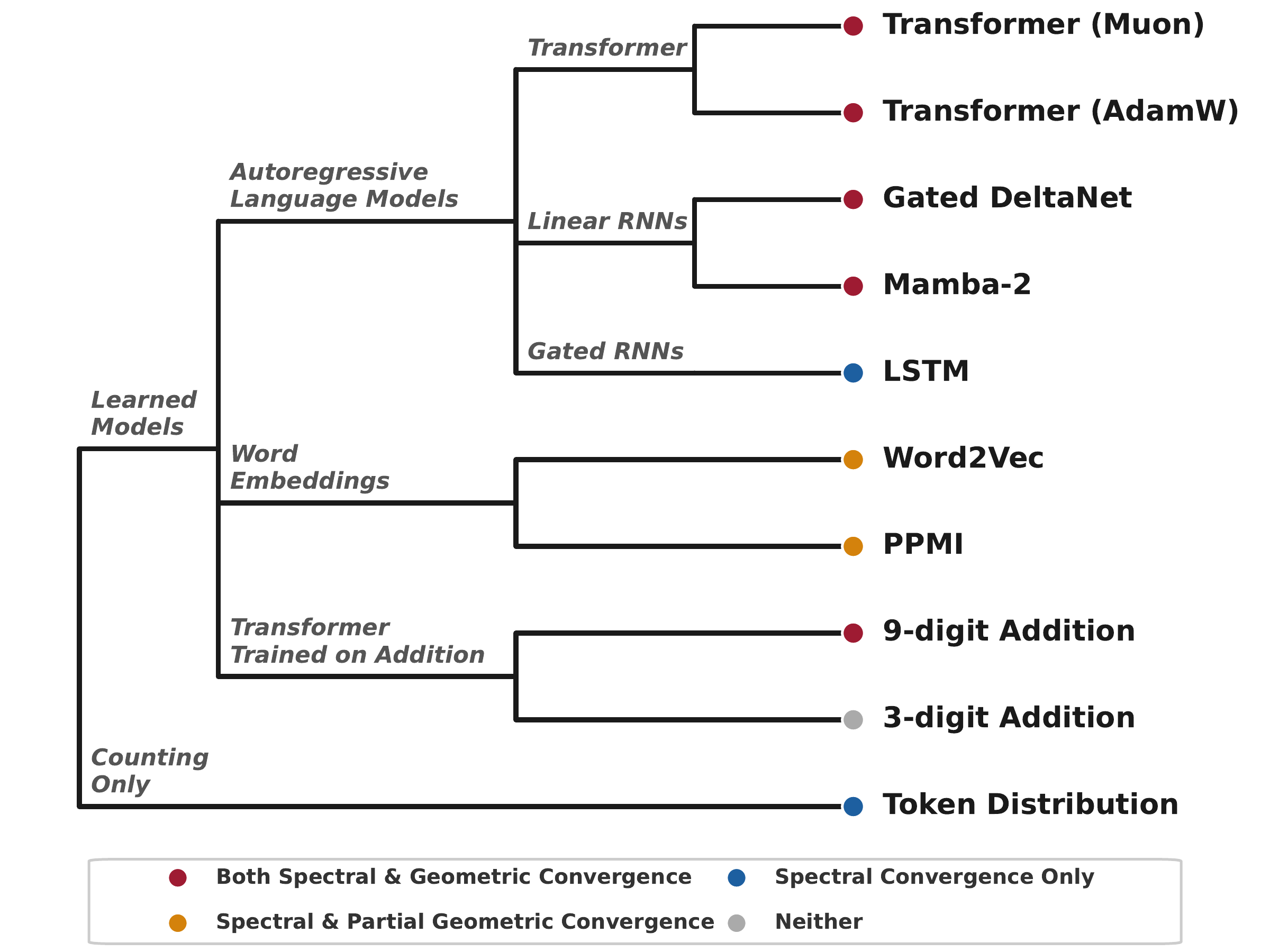
Holding data and compute constant, Transformers and two linear RNNs (Gated DeltaNet and Mamba-2) all learn geometrically separable mod-T features, while the LSTM sits near chance on the probe even though its Fourier spikes are as visible as the Transformer's. A shallower (4-layer) LSTM shows no improvement either, so the failure is architectural rather than a matter of capacity. In fact, the LSTM's Fourier spectrum closely resembles the number-token marginal distribution, suggesting its embeddings capture little beyond unigram frequency statistics.
The optimizer is not a cosmetic choice at the representation level, and its effect is architecture-dependent. Muon improves probing for the Transformer (κ = 85.4 vs 72.1 at $T=10$) and Gated DeltaNet (77.8 vs 69.7), but Mamba-2 prefers AdamW (80.1 vs 76.7). The Transformer trained with Muon has the strongest probe overall. We see no universal winner across architectures.
Classical baselines put this in perspective. PPMI and word2vec trained on the same 10B tokens show clear Fourier spikes but only moderate probing (κ = 27.1 and 29.3 at $T = 10$), a clean instance of the spectral/geometric dissociation outside the modern LLM regime.
A second route: arithmetic training
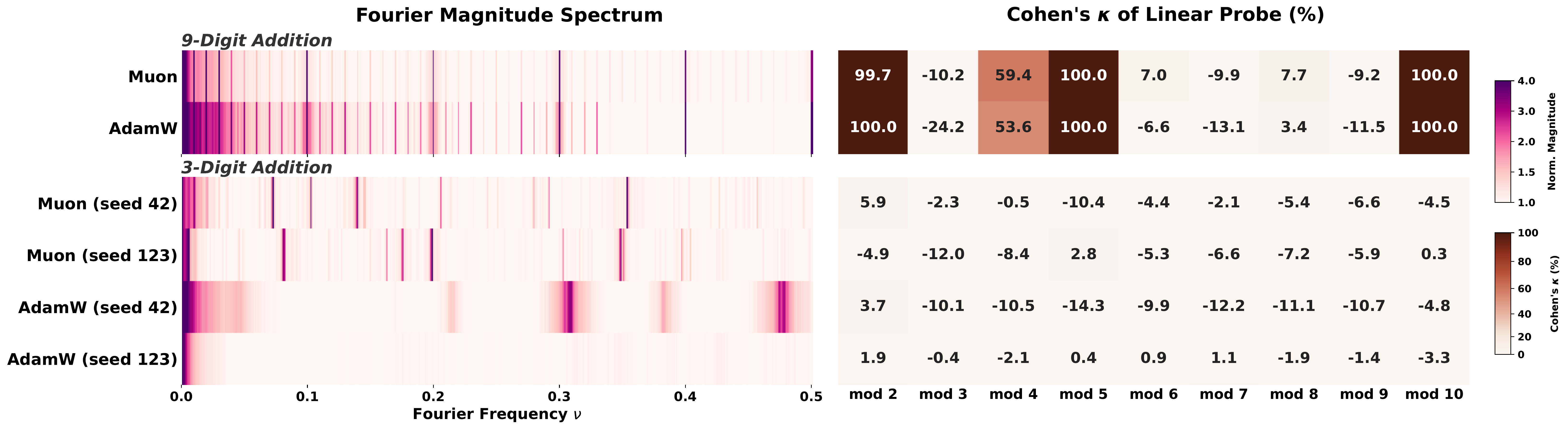
Pretraining on general text is not the only route. Training from scratch on addition can also induce geometrically separable periodic features, but only in the multi-token setting. In 9-digit addition, each output token $c_i$ satisfies
$$c_i = (a_i + b_i + \gamma_i) \bmod 1000,$$
where $\gamma_i \in \{0, 1\}$ is the carry. Each output position is therefore a mod-1000 classification problem. Because our models use tied embeddings, the output logits depend directly on the embedding matrix, so there is direct pressure for the embeddings to develop non-trivial $\Phi_{1000}$, and hence non-trivial $\Phi_T$ for all $T$ dividing $1000 = 2^3 \cdot 5^3$.
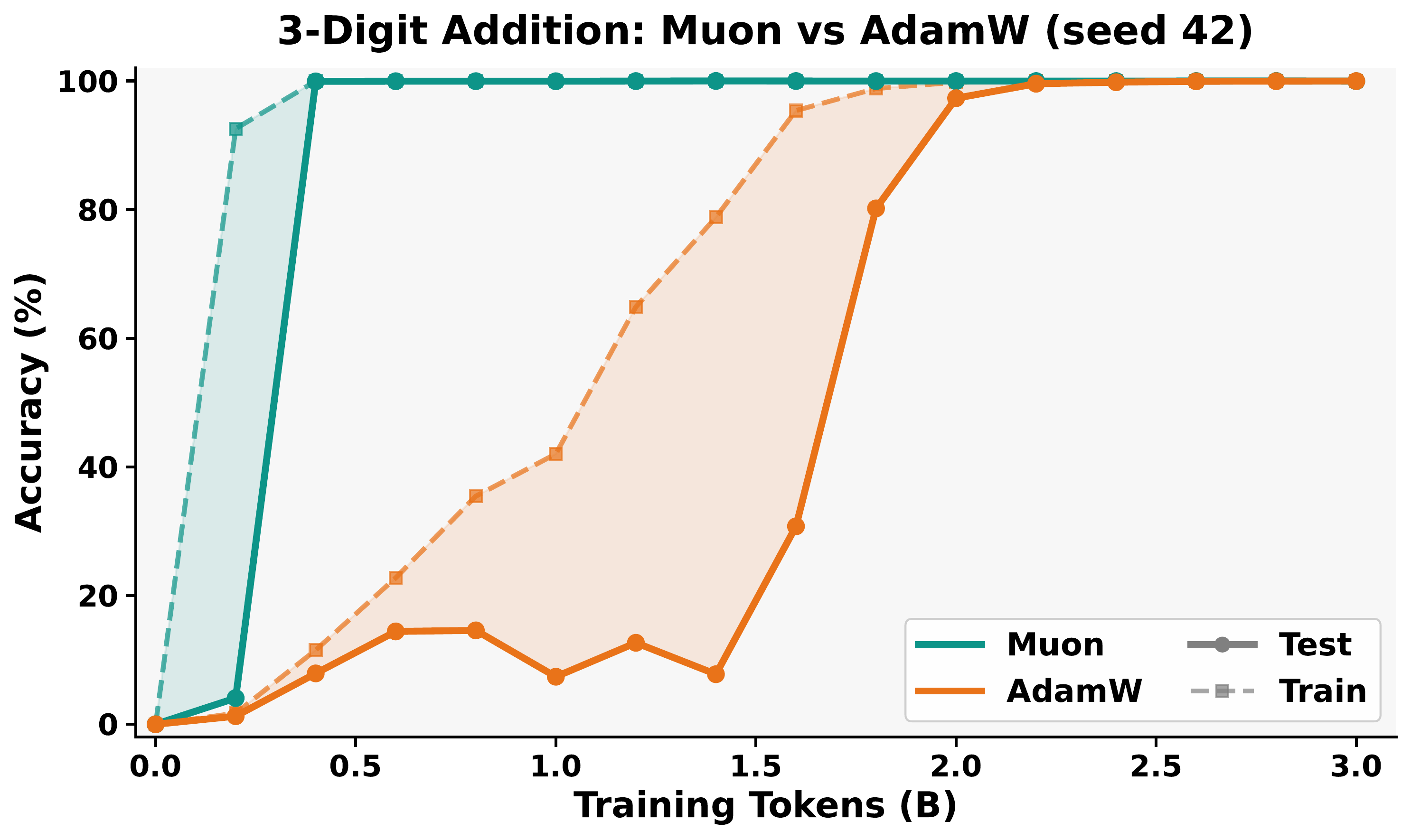
In single-token (3-digit) addition, there is no modular constraint. The sequences $a + b = c$ are identical whether interpreted as mod-1000 or mod-1111 arithmetic. The learned representations depend on optimizer and seed, and Fourier features emerge only sometimes.
Why “convergent evolution”?
In biology, convergent evolution is the independent emergence of similar traits in unrelated lineages facing shared environmental pressures. Eyes in vertebrates and cephalopods, wings in birds and bats, echolocation in bats and dolphins. The shared trait is evidence of a shared constraint, not a shared ancestor.
Fourier features in number embeddings fit the pattern. GPT, Mamba, LSTM, and word2vec share no architectural ancestry worth speaking of, but they all produce the same periodic spectrum. The shared constraint is the training distribution: number tokens occur at frequencies that are already periodic, and almost any learning process that digests this distribution inherits the periodicity.
But inheriting the spectrum is not the same as inheriting the function. Spectral convergence is universal. Geometric convergence requires the data, the architecture, and the optimizer to align, or else a training signal (like multi-token addition) that forces modular structure by construction.
Takeaways
- Fourier spikes are a weak diagnostic. Even the raw token frequency distribution has them. A spike in a model tells you about the training distribution, not necessarily about the model.
- The spectral/geometric hierarchy is real. Linearly decodable mod-T structure is a strictly stronger property than Fourier sparsity, and the two come apart both in theory and in practice.
- Structure attribution is a useful lens. Controlled perturbations of the training distribution let us attribute representations, not just predictions, to specific structural properties of the data.
- Multiple routes, same destination. Geometric convergence can arise from general text co-occurrence, or from multi-token arithmetic. The mechanism differs; the endpoint looks similar.
More broadly, we think the spectral/geometric distinction is a useful template for interpretability. As we increasingly rely on representation-level diagnostics to understand large models, it matters to distinguish visible structure from functional structure. They are not the same thing.
Related work
Click any citation to see the full title, authors, and venue.
Fourier features in number embeddings. Zhou et al. (2024) first showed that pretrained Transformers represent integer tokens with Fourier components and that addition is implemented through Fourier-domain circuits. Levy and Geva (2025) document related digit-base periodic structure in intermediate representations, and Kantamneni and Tegmark (2025) and Zhou et al. (2024) identify trigonometric circuits used in addition. Zhou et al. (2025, FoNE) show that hard-coding Fourier number embeddings improves arithmetic learning. Earlier, Gu et al. (2024) analyzed Fourier circuits in modular arithmetic. Cyclic representations have also been observed for non-numerical concepts such as days of the week and months of the year (Engels et al., 2025; Karkada et al., 2026). These works document spectral structure; we show this structure does not by itself imply geometric (linear) separability of mod-$T$ classes, and identify what does.
Modular arithmetic and grokking. Transformers trained on modular addition learn to embed numbers on a circle and rotate to compute the answer (Nanda et al., 2023; Zhong et al., 2023; Gromov, 2023; Power et al., 2022). In our 9-digit addition setting, the multi-token output forces a mod-1000 subproblem at every position, so circular structure emerges without a modular-arithmetic objective being explicitly imposed.
Linear representation hypothesis and probing. The linear representation hypothesis (Park et al., 2023) conjectures that high-level concepts should be linearly decodable from model representations; probing (e.g. Orgad et al., 2025) is the standard test. For cyclic concepts, our results show that linear decodability is a strictly stronger property than the spectral diagnostics prior work has often used as a stand-in.
Convergence of representations across models. The Platonic Representation Hypothesis (Huh et al., 2024) argues that representations across models and modalities are converging toward a shared statistical model of reality, measured via global kernel alignment. We ask a different question: when models converge on a similar representation of one specific concept (numbers), have they learned the same functional structure? Often, no.
Controlled studies of pretraining. Allen-Zhu (2025) uses controlled synthetic pretraining to isolate which capabilities emerge from which architectural and data choices. Our perturbations (Swap Numbers, Unigram Replace, Isolate-k, ContextLength-$\ell$) follow the same spirit, applied to natural pretraining data and aimed at the level of representations rather than capabilities.
Attribution. Influence functions (Koh and Liang, 2017; Grosse et al., 2023) and Data Shapley (Ghorbani and Zou, 2019) attribute model predictions to individual training examples. Our controlled perturbations are an analogue at the level of representations: they attribute emergent features to specific structural properties of the training distribution.
Acknowledgments
We thank the Center for Advanced Research Computing (CARC) at the University of Southern California and the USC NLP Group for compute. DF and RJ were supported by a gift from the USC–Capital One Center for Responsible AI and Decision Making in Finance (CREDIF). RJ was supported in part by NSF grant IIS-2403436. VS was supported by NSF grant CCF-2239265, an Amazon Research Award, a Google Research Scholar Award, and an Okawa Foundation Research Grant. This work used the Delta system at NCSA through allocation CIS250737 from the ACCESS program (NSF grants #2138259, #2138286, #2138307, #2137603, and #2138296). Portions of the work were done while some of the authors were visiting the Simons Institute for the Theory of Computing. GPU resources used to train and analyze the 300M-parameter models were provided through the NVIDIA Academic Grant Program.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not reflect the views of the funding agencies.
Citation
@misc{fu2026convergent,
title = {Convergent Evolution: How Different Language Models Learn Similar Number Representations},
author = {Deqing Fu and Tianyi Zhou and Mikhail Belkin and Vatsal Sharan and Robin Jia},
year = {2026},
eprint = {2604.20817},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2604.20817}
}